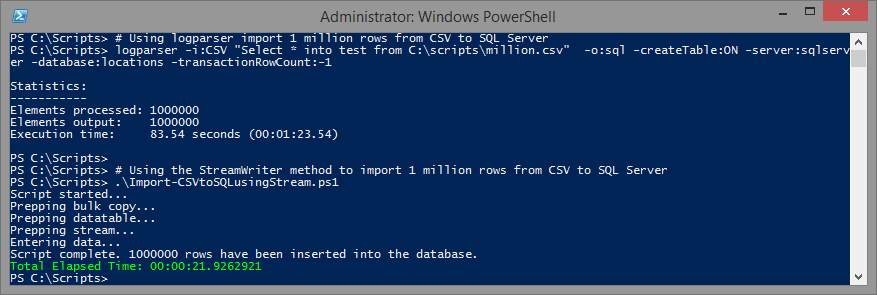
High-Performance Techniques for Importing CSV to SQL Server using PowerShell
If you've ever tried to use PowerShell's Import-CSV with large files, you know that it can exhaust all of your RAM. Previously, I created a script on ScriptCenter that used an alternative technique to import large CSV files, and even imported them into SQL Server at a rate of 1.7 million rows a minute. I've now gotten that number up to a massive 3.2 million rows a minute 5.35 million rows a minute for non-indexed tables and 2.6 million rows a minute 4.35 million rows a minute for tables with clustered indexes.
Importing into SQL Server
Two of the fastest ways to import data is to use bcp or SqlBulkCopy. BCP is finicky, and requires a separate download. My intention is to create a script that can be used on any machine running PowerShell v3 and above, so these scripts will be using SqlBulkCopy. The catch is that SqlBulkCopy.WriteToServer() requires a Datatable, Datarow, or IDataReader as input. This means your plain-text CSV data must be transformed into one of these objects prior to being passed to WriteToServer().
I've tested three different methods for transforming CSV data to a consumable object. The first method uses SqlBulkCopy, StreamReader and DataSet batches. The second streams an OleDbconnection query result set to SqlBulkCopy. The third uses SqlBulkCopy, VisualBasic.FileIO.TextFieldParser and DataSet batches. I actually tested logparser, too, but while logparser is amazing (and way way faster) for parsing files, it doesn't take advantage of sqlbulkcopy, so these approaches actually outperform logparser (and my tests with SSIS for that matter).
Setup
My lab is a VMWare virtualized lab which now consists of a Windows 10 machine with 6GB RAM, and a SQL Server 2014 instance with 12GB RAM (8 dedicated to SQL Server). Both are on on the same ESX host which sports a directly connected Samsung 850 EVO 500GB SSD drive. The database's recovery model is set to SIMPLE.
The 1.2 GB CSV in this example contains 10 million+ rows of tab-delimited longitude and latitude data. A zip containing the CSV is available for download at geonames.org.
First, I had to create the SQL table.
1CREATE TABLE allCountries (
2 GeoNameId int PRIMARY KEY,
3 Name nvarchar(200),
4 AsciiName nvarchar(200),
5 AlternateNames nvarchar(max),
6 Latitude float,
7 Longitude float,
8 FeatureClass char(1),
9 FeatureCode varchar(10),
10 CountryCode char(2),
11 Cc2 varchar(255),
12 Admin1Code varchar(20),
13 Admin2Code varchar(80),
14 Admin3Code varchar(20),
15 Admin4Code varchar(20),
16 Population bigint,
17 Elevation varchar(255),
18 Dem int,
19 Timezone varchar(40),
20 ModificationDate smalldatetime,
21)
Then I tested the various methods. You'll probably notice that these scripts don't have much error handling. I wanted to keep the code easy to read and straightforward. Finalized scripts with error handling and all that will be placed on ScriptCenter shortly.
StreamReader to DataTable batches
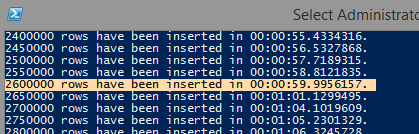
This one is by far the fastest, at up to 5.35 million rows per minute on a non-indexed table.
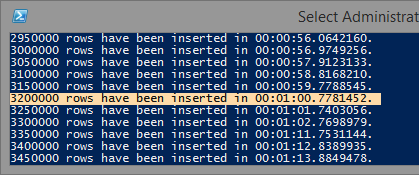
Realistically, you'll probably be importing to an indexed table, which performs up to 4.35 million rows per minute on optimized systems.
Basically, the script performs the following
- Creates the SQL Bulk Copy connection
- Creates the PowerShell datatable, along with its columns
- Reads the CSV file using System.IO.StreamReader
- Using readline(), loads the CSV data row by row into the datatable
- Performs the bulk import every x number of rows
- Empties the datatable
- Rinse repeat starting at step 4 until the end of the CSV file
In order to avoid having to specify column names each time you import a new CSV, the SQL table column order and CSV column order must be the same. If you need to rearrange your columns, I suggest creating a view and importing to the view.
If you're wondering why batching was used, it's because the datatable seems to get exponentially slower as it grows above a few hundred thousand rows. I actually wasn't able to import all 9 million rows into the datatable before my memory was exhausted. I tested various batch sizes, and 50k worked best for me.
The downside to using this script is that it doesn't handle embedded delimiters well. So if you have a comma delimiter, and your data contains "This Works","This, doesn't", then it will fail on "This, doesn't." You can address this with a regex (as seen below, after the code).
The Script
1# Database variables
2$sqlserver = "sqlserver"
3$database = "locations"
4$table = "allcountries"
5
6# CSV variables
7$csvfile = "C:\temp\allcountries.txt"
8$csvdelimiter = "`t"
9$firstRowColumnNames = $false
10
11################### No need to modify anything below ###################
12Write-Host "Script started..."
13$elapsed = [System.Diagnostics.Stopwatch]::StartNew()
14[void][Reflection.Assembly]::LoadWithPartialName("System.Data")
15[void][Reflection.Assembly]::LoadWithPartialName("System.Data.SqlClient")
16
17# 50k worked fastest and kept memory usage to a minimum
18$batchsize = 50000
19
20# Build the sqlbulkcopy connection, and set the timeout to infinite
21$connectionstring = "Data Source=$sqlserver;Integrated Security=true;Initial Catalog=$database;"
22$bulkcopy = New-Object Data.SqlClient.SqlBulkCopy($connectionstring, [System.Data.SqlClient.SqlBulkCopyOptions]::TableLock)
23$bulkcopy.DestinationTableName = $table
24$bulkcopy.bulkcopyTimeout = 0
25$bulkcopy.batchsize = $batchsize
26
27# Create the datatable, and autogenerate the columns.
28$datatable = New-Object System.Data.DataTable
29
30# Open the text file from disk
31$reader = New-Object System.IO.StreamReader($csvfile)
32$columns = (Get-Content $csvfile -First 1).Split($csvdelimiter)
33if ($firstRowColumnNames -eq $true) { $null = $reader.readLine() }
34
35foreach ($column in $columns) {
36 $null = $datatable.Columns.Add()
37}
38
39# Read in the data, line by line
40while (($line = $reader.ReadLine()) -ne $null) {
41 $null = $datatable.Rows.Add($line.Split($csvdelimiter))
42 $i++; if (($i % $batchsize) -eq 0) {
43 $bulkcopy.WriteToServer($datatable)
44 Write-Host "$i rows have been inserted in $($elapsed.Elapsed.ToString())."
45 $datatable.Clear()
46 }
47}
48
49# Add in all the remaining rows since the last clear
50if($datatable.Rows.Count -gt 0) {
51 $bulkcopy.WriteToServer($datatable)
52 $datatable.Clear()
53}
54
55# Clean Up
56$reader.Close(); $reader.Dispose()
57$bulkcopy.Close(); $bulkcopy.Dispose()
58$datatable.Dispose()
59
60Write-Host "Script complete. $i rows have been inserted into the database."
61Write-Host "Total Elapsed Time: $($elapsed.Elapsed.ToString())"
62# Sometimes the Garbage Collector takes too long to clear the huge datatable.
63[System.GC]::Collect()
As I mentioned earlier, you can use regex if you have delimiters embedded in quotes. This slows down the script by a fair degree, but here's some code to get you started.
1# from https://stackoverflow.com/questions/15927291/how-to-split-a-string-by-comma-ignoring-comma-in-double-quotes
2$fieldsEnclosedInQuotes = $true
3...
4if ($fieldsEnclosedInQuotes) {
5 $csvSplit = "($csvdelimiter)"
6 $csvsplit += '(?=(?:[^"]|"[^"]*")*$)'
7} else { $csvsplit = $csvdelimiter }
8$regexOptions = [System.Text.RegularExpressions.RegexOptions]::ExplicitCapture
9...
10$columns = [regex]::Split($firstline, $csvSplit, $regexOptions)
11...
12$null = $datatable.Rows.Add($([regex]::Split($line, $csvSplit, $regexOptions)))
Streaming a 32-bit OleDbconnection
What I like about this method is that it's still high performance (~2million rows/minute) and you can select subsets of data from CSV if you wish. Just change the CommandText to have a where clause, for example: $cmd.CommandText = "SELECT count(*) FROM [$tablename] WHERE Category='Cajun'". If your CSV doesn't have column names, you can use the built-in column names F1, F2, F3, etc.
Here are the results from a million row subset: 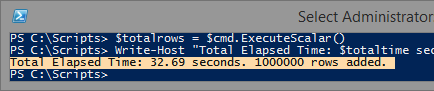
The downside to this script is that you have to use an x86 shell, but because it doesn't use any RAM, the performance actually isn't impacted. Switching to another shell may just get a little complex if you embed this script in a function. I've mitigated this to the best of my ability by telling it to call the 32-bit shell with the current scriptname and arguments.
The Script
1# The Text OleDB driver is only available in PowerShell x86. Start x86 shell if using x64.
2# This has to be the first check this script performs.
3if ($env:Processor_Architecture -ne "x86") {
4 Write-Warning "Switching to x86 shell"
5 $ps32exe = "$env:windir\syswow64\windowspowershell\v1.0\powershell.exe"
6 &$ps32exe "$PSCommandPath $args"; return
7}
8
9# Database variables
10$sqlserver = "sqlserver"
11$database = "locations"
12$table = "allcountries"
13
14# CSV variables
15$csvfile = "C:\temp\million.csv"
16$csvdelimiter = ","
17$firstRowColumnNames = $true
18
19################### No need to modify anything below ###################
20Write-Host "Script started..."
21$elapsed = [System.Diagnostics.Stopwatch]::StartNew()
22[void][Reflection.Assembly]::LoadWithPartialName("System.Data")
23[void][Reflection.Assembly]::LoadWithPartialName("System.Data.SqlClient")
24
25# Setup bulk copy
26$connectionstring = "Data Source=$sqlserver;Integrated Security=true;Initial Catalog=$database"
27$bulkcopy = New-Object Data.SqlClient.SqlBulkCopy($connectionstring, [System.Data.SqlClient.SqlBulkCopyOptions]::TableLock)
28$bulkcopy.DestinationTableName = $table
29$bulkcopy.bulkcopyTimeout = 0
30
31# Setup OleDB using Microsoft Text Driver.
32$datasource = Split-Path $csvfile
33$tablename = (Split-Path $csvfile -leaf).Replace(".","#")
34 switch ($firstRowColumnNames) {
35 $true { $firstRowColumnNames = "Yes" }
36 $false { $firstRowColumnNames = "No" }
37}
38$connstring = "Provider=Microsoft.Jet.OLEDB.4.0;Data Source=$datasource;Extended Properties='text;HDR=$firstRowColumnNames;FMT=Delimited($csvdelimiter)';"
39$conn = New-Object System.Data.OleDb.OleDbconnection
40$conn.ConnectionString = $connstring
41$conn.Open()
42$cmd = New-Object System.Data.OleDB.OleDBCommand
43$cmd.Connection = $conn
44
45# Perform select on CSV file, then add results to a datatable using ExecuteReader
46$cmd.CommandText = "SELECT * FROM [$tablename]"
47$bulkCopy.WriteToServer($cmd.ExecuteReader([System.Data.CommandBehavior]::CloseConnection))
48
49# Get Totals
50$totaltime = [math]::Round($elapsed.Elapsed.TotalSeconds,2)
51
52$conn.Close(); $conn.Open()
53$cmd.CommandText = "SELECT count(*) FROM [$tablename]"
54$totalrows = $cmd.ExecuteScalar()
55Write-Host "Total Elapsed Time: $totaltime seconds. $totalrows rows added." -ForegroundColor Green
56
57# Clean Up
58$cmd.Dispose(); $conn.Dispose(); $bulkcopy.Dispose()
VisualBasic.FileIO.TextFieldParser to DataTable batches
This technique is the slowest, but if you've got embedded delimiters and need to stay in x64, you may want to consider it.
The Script
1# Database variables
2$sqlserver = "sqlserver"
3$database = "locations"
4$table = "allcountries"
5
6# CSV variables
7$parserfile = "C:\temp\million.csv"
8$parserdelimiter = ","
9$firstRowColumnNames = $false
10$fieldsEnclosedInQuotes = $true
11
12################### No need to modify anything below ###################
13Write-Host "Script started..."
14$elapsed = [System.Diagnostics.Stopwatch]::StartNew()
15[void][Reflection.Assembly]::LoadWithPartialName("System.Data")
16[void][Reflection.Assembly]::LoadWithPartialName("System.Data.SqlClient")
17[void][Reflection.Assembly]::LoadWithPartialName("Microsoft.VisualBasic")
18
19# 50k worked fastest and kept memory usage to a minimum
20$batchsize = 50000
21
22# Build the sqlbulkcopy connection, and set the timeout to infinite
23$connectionstring = "Data Source=$sqlserver;Integrated Security=true;Initial Catalog=$database;"
24$bulkcopy = New-Object Data.SqlClient.SqlBulkCopy($connectionstring, [System.Data.SqlClient.SqlBulkCopyOptions]::TableLock)
25$bulkcopy.DestinationTableName = $table
26$bulkcopy.bulkcopyTimeout = 0
27$bulkcopy.batchsize = $batchsize
28
29# Open text parser for the column names
30$columnparser = New-Object Microsoft.VisualBasic.FileIO.TextFieldParser($parserfile)
31$columnparser.TextFieldType = "Delimited"
32$columnparser.HasFieldsEnclosedInQuotes = $fieldsEnclosedInQuotes
33$columnparser.SetDelimiters($parserdelimiter)
34
35Write-Warning "Creating datatable"
36$datatable = New-Object System.Data.DataTable
37foreach ($column in $columnparser.ReadFields()) {[void]$datatable.Columns.Add()}
38$columnparser.Close(); $columnparser.Dispose()
39
40# Open text parser again from start (there's no reset)
41$parser = New-Object Microsoft.VisualBasic.FileIO.TextFieldParser($parserfile)
42$parser.TextFieldType = "Delimited"
43$parser.HasFieldsEnclosedInQuotes = $fieldsEnclosedInQuotes
44$parser.SetDelimiters($parserdelimiter)
45if ($firstRowColumnNames -eq $true) {$null = $parser.ReadFields()}
46
47Write-Warning "Parsing CSV"
48while (!$parser.EndOfData) {
49 try { $null = $datatable.Rows.Add($parser.ReadFields()) }
50 catch { Write-Warning "Row $i could not be parsed. Skipped." }
51
52 $i++; if (($i % $batchsize) -eq 0) {
53 $bulkcopy.WriteToServer($datatable)
54 Write-Host "$i rows have been inserted in $($elapsed.Elapsed.ToString())."
55 $datatable.Clear()
56 }
57}
58
59# Add in all the remaining rows since the last clear
60if($datatable.Rows.Count -gt 0) {
61 $bulkcopy.WriteToServer($datatable)
62 $datatable.Clear()
63}
64
65Write-Host "Script complete. $i rows have been inserted into the database."
66Write-Host "Total Elapsed Time: $($elapsed.Elapsed.ToString())"
67
68# Clean Up
69#$parser.Dispose(); $bulkcopy.Dispose(); $datatable.Dispose();
70
71$totaltime = [math]::Round($elapsed.Elapsed.TotalSeconds,2)
72Write-Host "Total Elapsed Time: $totaltime seconds. $i rows added." -ForegroundColor Green
73# Sometimes the Garbage Collector takes too long to clear the huge datatable.
74[System.GC]::Collect()
VB.NET Equivalent
Using a VB.NET compiled exe imports about 4 million rows a minute.
1Sub Main()
2
3 Dim oTimer As New System.Diagnostics.Stopwatch
4 oTimer.Start()
5 Dim iRows As Int64 = 0
6
7 Using oBulk As New Data.SqlClient.SqlBulkCopy("server=.;database=DATABASE;trusted_connection=yes", SqlClient.SqlBulkCopyOptions.TableLock) With
8 {.DestinationTableName = "AllCountries", .BulkCopyTimeout = 0, .BatchSize = 100000}
9
10 Using oSR As New IO.StreamReader("C:\allcountries.txt")
11 Using oDT As New DataTable
12
13 With oDT.Columns
14 .Add("GeoNameID", GetType(System.Int32))
15 .Add("Name", GetType(System.String))
16 .Add("AsciiName", GetType(System.String))
17 .Add("AlternateNames", GetType(System.String))
18 .Add("Latitude", GetType(System.Decimal))
19 .Add("Longitude", GetType(System.Decimal))
20 .Add("FeatureClass", GetType(System.String))
21 .Add("FeatureCode", GetType(System.String))
22 .Add("CountryCode", GetType(System.String))
23 .Add("Cc2", GetType(System.String))
24 .Add("Admin1Code", GetType(System.String))
25 .Add("Admin2Code", GetType(System.String))
26 .Add("Admin3Code", GetType(System.String))
27 .Add("Admin4Code", GetType(System.String))
28 .Add("Population", GetType(System.Int64))
29 .Add("Elevation", GetType(System.String))
30 .Add("Dem", GetType(System.Int32))
31 .Add("Timezone", GetType(System.String))
32 .Add("ModificationDate", GetType(System.DateTime))
33 End With
34 Dim iBatchsize As Integer = 0
35
36 Do While Not oSR.EndOfStream
37 Dim sLine As String() = oSR.ReadLine.Split(vbTab)
38 oDT.Rows.Add(sLine)
39 iBatchsize += 1
40 If iBatchsize = 100000 Then
41 oBulk.WriteToServer(oDT)
42 oDT.Rows.Clear()
43 iBatchsize = 0
44 Console.WriteLine("Flushing 100,000 rows")
45 End If
46 iRows += 1
47 Loop
48 oBulk.WriteToServer(oDT)
49 oDT.Rows.Clear()
50 End Using
51 End Using
52 End Using
53 oTimer.Stop()
54 Console.WriteLine(iRows.ToString & "Records imported in " & oTimer.Elapsed.TotalSeconds & " seconds.")
55 Console.ReadLine()
56
57End Sub
Conclusion
There are a number of tools that can be used to import CSV files into SQL Server. If you're looking to use PowerShell, the StreamReader will give you the fastest results, but if your code has embedded delimiters, this may not be the method for you. Using OleDBConnection is a powerful, fast way to import entire CSVs or subsets of CSV data, but requires the use of an x86 shell, unless you download the Microsoft Access Database Engine 2010 Redistributable which provides a 64-bit text driver. Microsoft.VisualBasic.FileIO.TextFieldParser is slower, but works in 64-bit and processes embedded delimiters well.