Import-DbaCsv Design Considerations
This post is about Import-DbaCsv, a command within the dbatools PowerShell module for SQL Server.
I've been writing about CSV imports using PowerShell for a pretty long time and in VBScript for even longer. Initially, my primary concerns were ease-of-use and speed. Over time, I realized that what mattered most was:
- Ease-of-use
- Reliability
- Data quality management
I learned a ton about performance from my speed experiments but in the end, I threw most of that out in favor of a higher quality and mildly slower solution using a .NET compiled library called LumenWorks.Framework.IO.
The best part about using LumenWorks instead of rolling my own solution is that it handles imperfect data very well. My solutions were fast but had no error handling and only the cleanest of CSVs would work. Clean CSVs are ideal but not always found in real-world data sets.
Ease-of-use
Ease and enjoyment is extremely important when designing and using a tool because if something is a headache to use, you'll probably start avoiding it. Like me with the Import and Export Wizard. I haven't used it in over a decade, because nearly every time I tried, this happened:
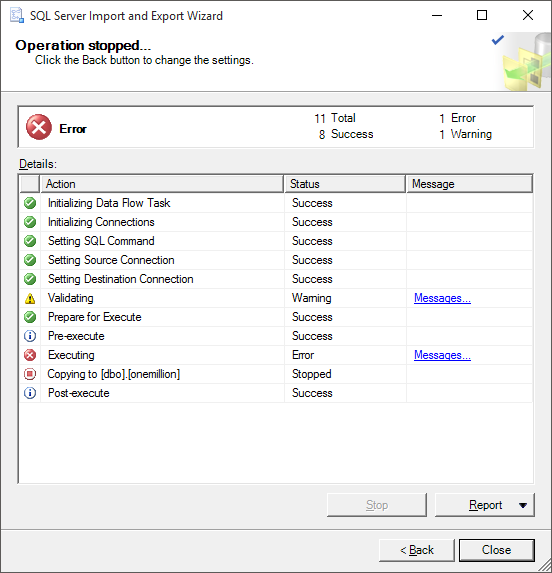
Ughhh just figure it out and let me import my data! Initial versions of Import-DbaCsv only accepted perfect data too, though, so I get it ¯\(ツ)/¯.
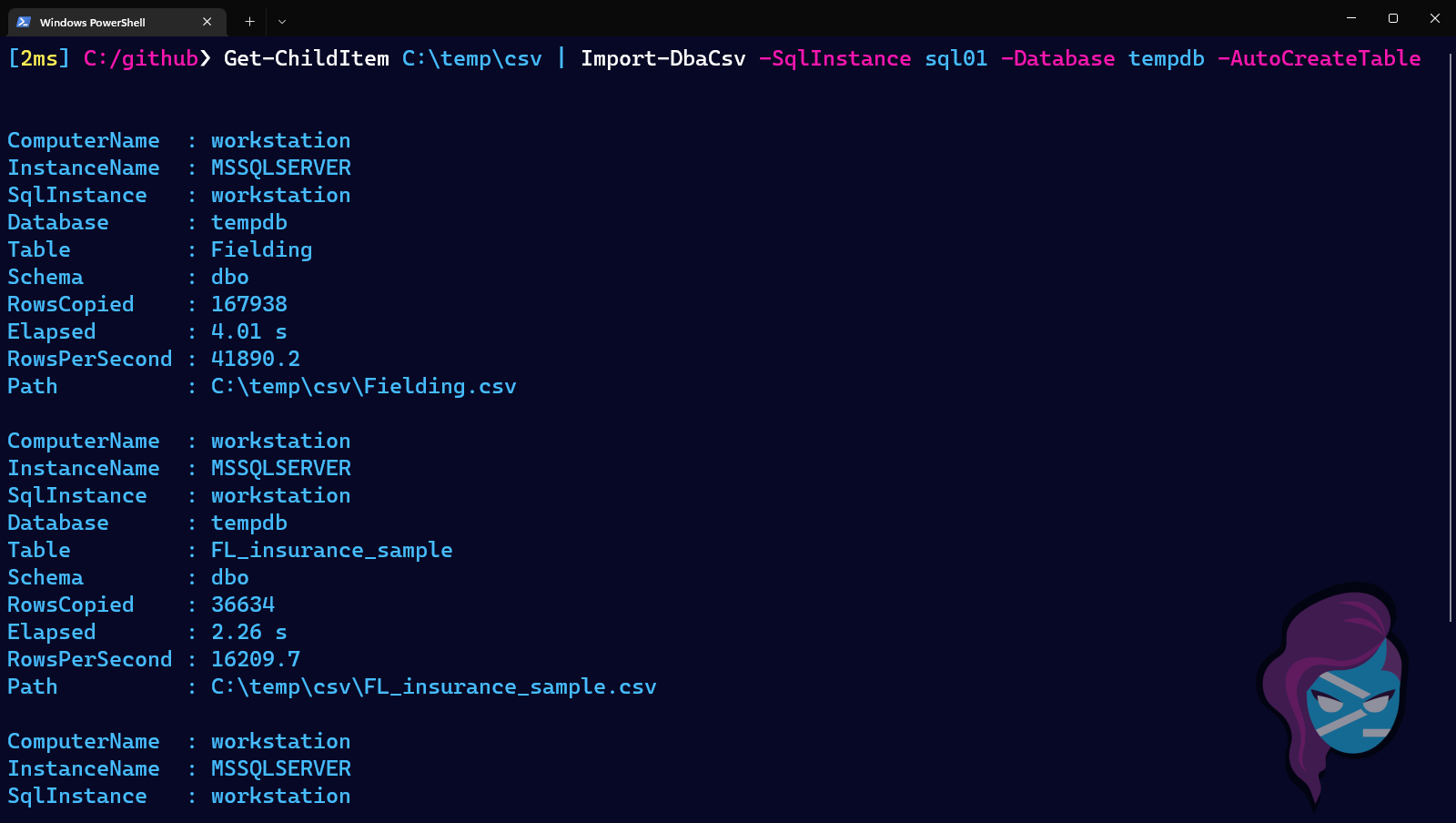
Now, Import-DbaCsv just figures everything out and lets you import your data, whether it's perfect or not. When it comes to ease-of-use, it really can't get any easier than this to import a whole directory full of varied CSVs:
1Get-ChildItem C:\temp\csv | Import-DbaCsv -SqlInstance sql01 -Database tempdb -AutoCreateTable
This will get a list of all CSV files in C:\temp\csv, then import them to the tempdb database on sql01, using the basename of the file as the table name. If the table doesn't already exist, it'll auto-create it using nvarchar(MAX), which is inefficient/slow but guaranteed to be big enough.
Once the data has been imported, you can massage this data however you like within SQL Server, which is much more suited for data manipulation than PowerShell due to the focus and power of T-SQL.
As suggested by Import-DbaCsv's verbose messages, if you're looking for the fastest import possible, you should pre-create the table with appropriate datatypes. But if you just want the data in SQL Server with no fuss, -AutoCreateTable will do.
Pre-creating tables to increase performance
Here's the DDL of a sample table which was automatically created to accommodate a CSV import.
1CREATE TABLE allcountries (
2 GeoNameId nvarchar(max) NULL,
3 Name nvarchar(max) NULL,
4 AsciiName nvarchar(max) NULL,
5 AlternateNames nvarchar(max) NULL,
6 Latitude nvarchar(max) NULL,
7 Longitude nvarchar(max) NULL,
8 FeatureClass nvarchar(max) NULL,
9 FeatureCode nvarchar(max) NULL,
10 CountryCode nvarchar(max) NULL,
11 Cc2 nvarchar(max) NULL,
12 Admin1Code nvarchar(max) NULL,
13 Admin2Code nvarchar(max) NULL,
14 Admin3Code nvarchar(max) NULL,
15 Admin4Code nvarchar(max) NULL,
16 Population nvarchar(max) NULL,
17 Elevation nvarchar(max) NULL,
18 Dem nvarchar(max) NULL,
19 Timezone nvarchar(max) NULL,
20 ModificationDate nvarchar(max) NULL
21)
This resulted in an import of 4.4 million rows in 2 minutes and 4 seconds, or 35446 rows per second.
1ComputerName : workstation
2InstanceName : MSSQLSERVER
3SqlInstance : workstation
4Database : tempdb
5Table : allcountries
6Schema : dbo
7RowsCopied : 4400000
8Elapsed : 00:02:04
9RowsPerSecond : 35446.7
10Path : C:\Archive\csv\allcountries.csv
Acceptable enough, especially for a wide table. The import can be sped up by creating more accurate data types, however. After optimizing the datatypes for the data that will actually be in the table, the DDL looks like this:
1CREATE TABLE allcountries (
2 GeoNameId int PRIMARY KEY,
3 Name nvarchar(200),
4 AsciiName nvarchar(200),
5 AlternateNames nvarchar(max),
6 Latitude float,
7 Longitude float,
8 FeatureClass char(1),
9 FeatureCode varchar(10),
10 CountryCode char(2),
11 Cc2 varchar(255),
12 Admin1Code varchar(20),
13 Admin2Code varchar(80),
14 Admin3Code varchar(20),
15 Admin4Code varchar(20),
16 Population bigint,
17 Elevation varchar(255),
18 Dem int,
19 Timezone varchar(40),
20 ModificationDate smalldatetime,
21)
This resulted in an import of 4.4 million rows in about 59 seconds, or 74754 rows per second. This doubles the performance!
1ComputerName : workstation
2InstanceName : MSSQLSERVER
3SqlInstance : workstation
4Database : tempdb
5Table : allcountries
6Schema : dbo
7RowsCopied : 4400000
8Elapsed : 58.86 s
9RowsPerSecond : 74754.9
10Path : C:\Archive\csv\allcountries.csv
If you did just stuff your data into the database, you can use INSERT...SELECT to import the data into the properly structured table. In my case, it took 32 seconds to insert 4.4 million rows from the import table to the optimized table.
Reliability
The most important part of importing data is that the data remains the same. But I found that some data could disappear if multithreading was used. Multithreading got me up to 260,000 rows per second for some data sets, but sometimes like 4 rows out of millions would be missing. Not good enough, it needs to be perfect.
I've seen this behavior in other PowerShell runspace/multithreading projects (C# can deliver perfection but PS and multithreading is complicated), so by default, I removed runspaces which reduced the import speed by half. That was hard to let go of, but opened me up to using a third-party solution like LumenWorks.
Data quality management
As I mentioned earlier, real-world CSVs are filled with imperfect data. For example, let's say that you have a CSV and it uses quotes when a comma is present in the actual data.
1101152, Skies of Ores Sunblock, "This 30 SPF sunblock is light, scent-free and safe for all skin types."
This has to be handled within the importer, because if the data is imported as-is, the quotes will be included in the database and that's not what we want.
Handling this data introduced nanosecond slowdowns so my initial projects didn't support it because I was obsessed with speed. As it turns out, though, most CSVs contain these types of exceptions, so most people couldn't even use initial versions of Import-DbaCsv (then called Import-CsvToSql) to import their data.
When I let go of my dreams of achieving speeds that matched bcp (a program compiled in c, which is known for its blazing speeds even moreso than other compiled languages), I ended up with a smarter tool that works for most people and most datasets.
My favorite things
It's near impossible to quickly (milliseconds) determine how many rows are going to be uploaded within in a large file. Because of this, I couldn't add a progress bar for the rows left to upload, but I could show how many rows were imported and the elapsed time, updated every 50,000 rows.
SqlInstance : workstation Database : tempdb Importing from C:\temp\csv\Fielding.csv Progress: 850000 rows in 12.73 seconds RowsPerSecond : 62300.2 Path : C:\temp\csv\Sales.csv ComputerName : workstation InstanceName : MSSQLSERVER
I also like the output, which includes things I'm always curious about.
1ComputerName : workstation
2InstanceName : MSSQLSERVER
3SqlInstance : workstation
4Database : tempdb
5Table : AirlineDemoSmall
6Schema : dbo
7RowsCopied : 600000
8Elapsed : 4.99 s
9RowsPerSecond : 120168.2
10Path : C:\temp\csv\AirlineDemoSmall.csv
I appreciate that Import-DbaCsv just makes it so easy to import a bunch of CSVs, especially when I'm using it for my own projects. Yeah, the newly created tables are inefficient but the data is there and I can just use that table structure to create a new table and go about my day.
My most favorite thing, though, is feeling confident that Lumenworks will properly import user data, even at the expense of speed.